This post describes a production-ready customer support agent that runs inside WordPress while delegating orchestration and tools to a secure backend. It’s engineered for reliability, observability, and low latency.
Use case
– Answer product and account questions for a WooCommerce site
– Escalate to human when confidence is low
– Take actions: lookup orders, issue refunds (guardrails), update tickets, send emails
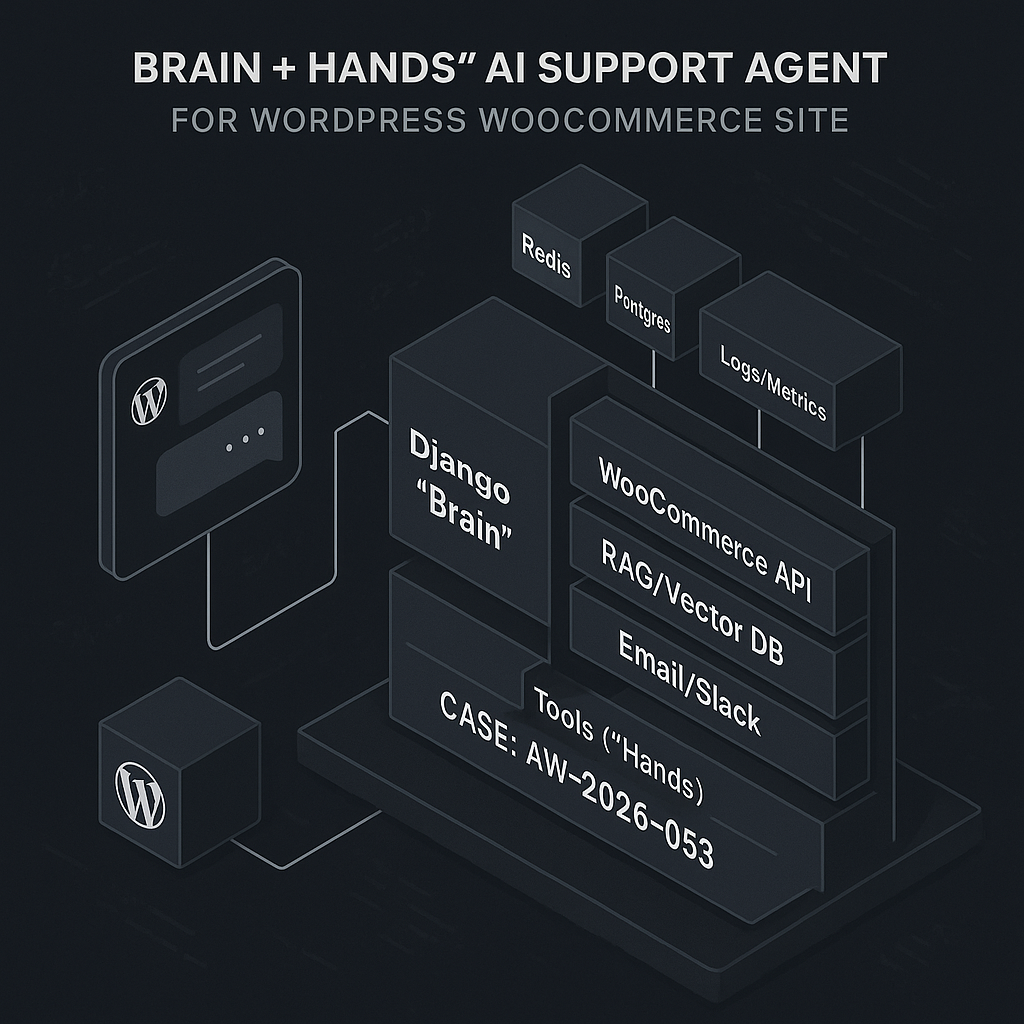
High-level architecture
– Frontend (WordPress plugin)
– Chat UI + streaming
– Session auth via signed JWT from WP
– Minimal logic; forwards events to backend
– Brain (Django service)
– Orchestrator with policy, planning, and tool routing
– Provider-agnostic LLM client with timeouts, retries, circuit breakers
– Memory: short-term conversation state + RAG for docs + customer context
– Hands (tools)
– WooCommerce API (read + guarded write)
– Vector search for KB (Postgres pgvector or Pinecone)
– Email/Slack/webhook notifications
– Ticketing (GitHub Issues, Linear, or HelpScout)
– Infra
– Postgres (sessions, logs, transcripts, evals)
– Redis (queues, rate limits, short-term state)
– Celery/RQ workers for long I/O tasks
– S3/GCS for attachments
– Nginx + Gunicorn/Uvicorn
– Feature flags via environment or LaunchDarkly
Brain + Hands separation
– Brain responsibilities
– Interpret user intent, decide tool plans, enforce policies
– Choose between “answer from RAG” vs “call WooCommerce” vs “escalate”
– Keep tight token budgets and latency budgets
– Hands responsibilities
– Deterministic, audited side effects
– Strict schemas, input validation, and permission checks
– Idempotent operations with clear error codes
Data model (Postgres)
– users: wp_user_id, email, roles
– sessions: session_id, user_id, created_at, last_seen
– messages: session_id, role, content, tool_calls, latencies
– kb_docs: id, url, title, chunk_id, embedding
– eval_runs: scenario_id, score, metrics, model, timestamp
– actions_log: tool_name, request, response, status, cost
Tooling interfaces (Hands)
– Tool schema example
– name: get_order_status
– input: {order_id: string}
– output: {status, items[], total, updated_at}
– errors: NOT_FOUND, UNAUTHORIZED, RATE_LIMIT, UPSTREAM_5XX
– Guarded write tool
– name: issue_refund
– preconditions: user identity verified, order within policy window, amount soft_limit
– RAG search tool
– name: kb_search
– input: {query: string, top_k: int<=5}
– output: [{title, url, snippet, score}]
– Messaging tools
– name: notify_human
– name: create_ticket
Prompting and policies (Brain)
– System prompt
– You are a support agent for ACME Store. Answer strictly from tools or KB. If unsure, escalate.
– Never fabricate order details. Use get_order_status.
– For refunds, always run verify_identity then check_refund_policy.
– Summarize actions taken at the end, link to sources.
– Planning logic
– If user mentions an order identifier → get_order_status
– If how-to/product question → kb_search then compose
– If policy question not in KB → escalate
– Style rules
– Short answers, steps, and links to sources
– Don’t expose internal error traces
Memory strategy
– Short-term: last 10 messages in Redis keyed by session_id
– Long-term: store all messages in Postgres for analytics
– Entity memory: customer profile (name, last orders, subscription) fetched on session start, cached 15 minutes
– RAG: nightly KB crawl (docs, FAQs, policies), chunked and embedded; invalidate on content updates
Orchestration flow
1) WP plugin sends user message + session_id to Django
2) Brain assembles context: last 10 messages, customer profile, latency budget
3) Brain calls plan() to choose tools
4) Execute tool calls with timeouts and retries (exponential backoff, jitter)
5) If tools fail with 5xx, trigger fallback: reduced context + alternative provider
6) Compose final answer with citations
7) Stream tokens back to WP; log telemetry
Error handling and guardrails
– Timeouts: 2.5s LLM planning; 3s tool I/O (retry up to 2x)
– Circuit breakers: open per-tool after 5 failures/60s, route to fallback answer + escalate
– Input validation: pydantic/dataclasses schemas for all tool inputs
– PII scrubbing before logs; hashed identifiers
– Rate limits: per-user and global; shed load with friendly message
– High-risk actions (refunds) require dual confirmation path or human approval token
Latency and cost controls
– Small model for planning, larger model only when composing long answers
– Token budget caps by policy; truncate history with windowing
– Cache KB search for 60s per session
– Turn off streaming if bandwidth-constrained; send final only
Observability
– Structured logs: request_id, session_id, tool_name, duration_ms, token_usage, cost_usd
– Traces: OpenTelemetry spans around LLM calls and tools
– Dashboards: success rate, handoffs, mean latency, top errors, containment rate
– Red-teaming playbook: simulate tricky prompts weekly; auto-generate counterfactual tests
Evaluation harness
– Scenarios: “Where is my order?”, “Refund outside window”, “Change shipping address”
– Metrics: exactness, policy adherence, source coverage, latency
– Offline evals on synthetic+real transcripts
– Canary release: 5% traffic to new Brain version, compare containment and CSAT
WordPress integration (plugin)
– Shortcode to render chat widget
– Auth: WP nonce → backend JWT (scoped to session only)
– Endpoints
– POST /chat/send
– GET /chat/stream?session_id=…
– POST /webhooks/order_updated
– Admin settings
– Backend URL, API key, rate limit per minute
– Feature flags: enable_refunds, enable_streaming
– Privacy: transcript retention days, PII masking rules
Security notes
– Store only necessary fields; encrypt at rest
– Strict CORS and allowed origins
– Signed webhooks for WooCommerce events
– Secrets via env vars (no secrets in WP DB)
Deployment checklist
– Docker images for Django API and workers
– Nginx reverse proxy with request size and timeout limits
– Postgres + Redis managed services
– Migrate DB, seed KB embeddings
– Health checks, readiness probes
– Runbooks for incident response and on-call rotation
Model/providers
– Start: gpt-4o-mini or claude-3-haiku for planning; gpt-4o or claude-3.5-sonnet for final answers
– Fall back chain: Provider A → Provider B → cached KB-only answer → human handoff
– Track provider performance per scenario; auto-shift traffic via feature flags
Rollout plan
– Week 1: shadow mode (agent suggests, human replies)
– Week 2: low-risk actions enabled, no refunds
– Week 3: enable refunds under $50 with approval token
– Ongoing: weekly evals, error budget, model updates behind canaries
What to build first
– KB pipeline (crawler, chunker, embeddings)
– Minimal Brain with plan() + kb_search + compose
– Observability + eval harness
– Then add WooCommerce read tools, finally guarded write tools
This blueprint keeps WordPress simple and pushes orchestration, policy, and tools into a hardened backend. You get fast responses, safe actions, measurable performance, and a path to scale.